使用啄木鸟下载器自定义模板配置功能可以针对某个网站的网页代码进行正则表达式配置,使得软件可以动态的扩充支持的网站。
本文读者及使用用户需具备以下能力:
1)了解html、javascript、css、ajax等基本的网页前端技术;
2)熟练使用Chrome浏览器的开发者工具;
3)熟练使用正则表达式及工具;
4)拥有自我学习和解决问题的能力;
除了官网发布的教程,我们并不提供任何的技术指导,不具备上述技术能力的用户可以私人定制来实现。
官网还有另一篇文章较为简单,参考:通用网站使用教程。相比通用模板,本文的方法稍复杂,但下载的图片会更加精准,可以满足更加个性化的要求。
下面以 https://www.zhongyiminghua.com/photos-index-aid-941.art 为例
相比通用下载,意:写下此文的时间是2019.12.08,
注意:写下此文的时间是2019.12.08,仅针对当前此网页有效。因为目标网站会随时改版,一旦改版对应的规则就要随之改变,仅以此文介绍软件的功能是如何使用的。
结合软件图文说明:
1. 创建并保存
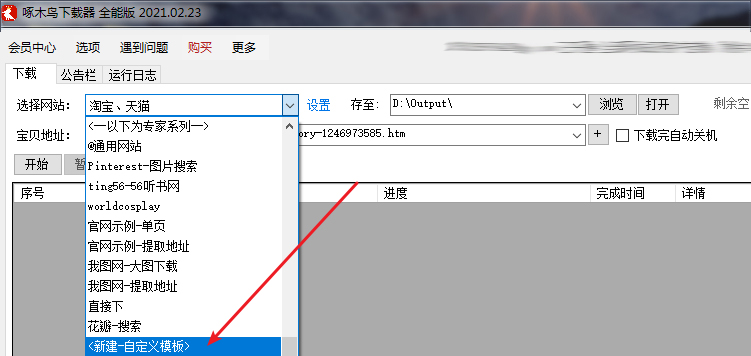
打开啄木鸟下载器全能版,下拉框选择“<新建-自定义模板>”
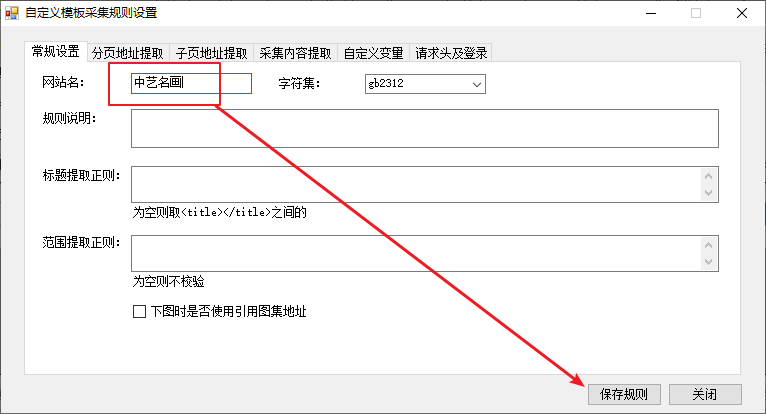
弹出自定义模板采集规则设置对话框,在网站名称处,输入“大众点评-店铺图片”,保存。
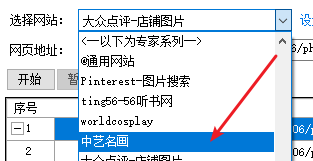
此后网站列表中已经有“中艺名画”这个网站可供选择了。
2. 设置采集规则
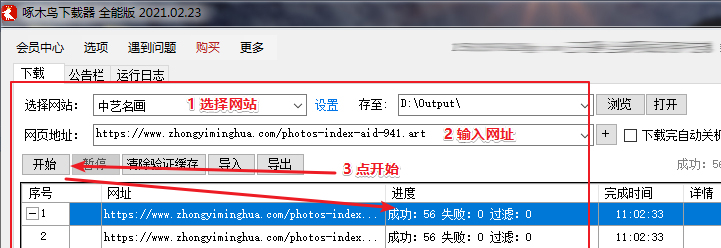
选择”中艺名画”网站,点击右侧的“设置”,弹出“中艺名画” 规则定义对话框,我们的目标通过设置,把全部图片都能一次性的下载。
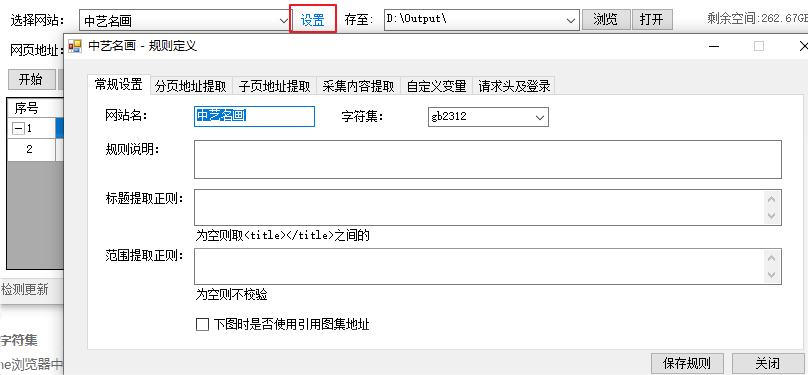
2.1 设置字符集
在Chrome浏览器中,打开目标网址,查看网页源代码。查看网页源代码,页面开始的字符集为utf-8,所以规则定义对话框中的“字符集”选择uft-8。
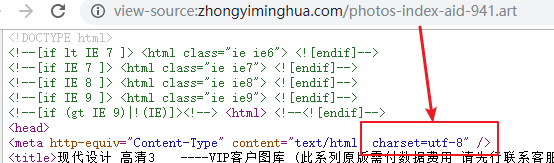
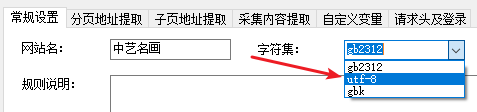
2.2 设置范围提取规则
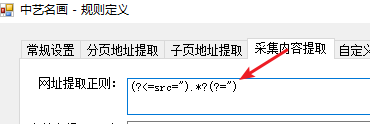
我们的目标是提取红框内的图片,查看网页源代码,通过分析,用 (?<=id="waterfall").*?(?=class="paginator") 的正则表达式匹配到的内容就是我们的图片所在的范围,所以规则定义对话框中的“范围提取规则”处填写黄色部分的正则表达式。

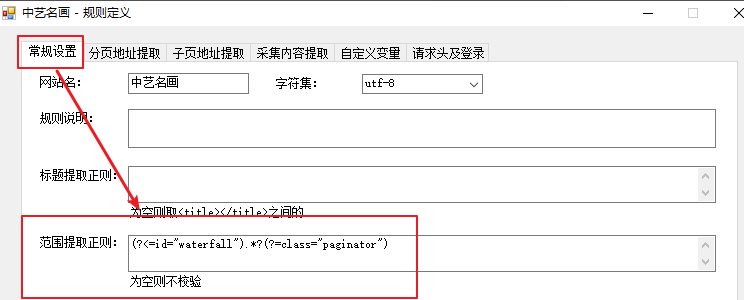
2.3 设置图片提取规则
我们的目标是提取列表中的图片,查看网页源代码,通过分析,用 (?<=src=").*?(?=") 的正则表达式匹配到的内容就是我们需要的图片,所以规则定义对话框中的“图片提取规则”处填写黄色部分的正则表达式。一共能够匹配56个。

配置到这里,其实软件已经可以开始工作了。
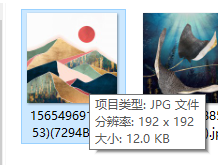
我们发现,下载下来的是小图,不能够达到我们的要求。所以还需要进一步的调整。
2.4 设置图片地址替换规则
我们需要的当然是清晰的大图,查看网页源代码,通过分析对比原图:
我们提取到的是缩略图:https://www.zhongyiminghua.com/data/t/0009/41/1565497026335.jpg
而大图的地址是 :https://www.zhongyiminghua.com/data/0009/41/1565497026335.jpg
缩略图多了/t,只需要把/t去掉就好了。
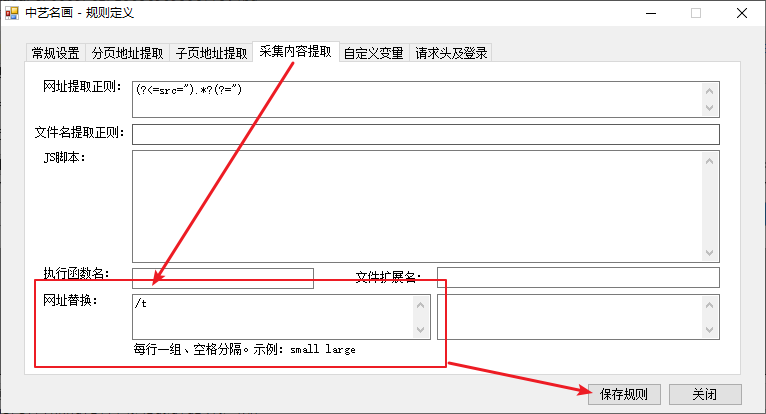
在网址替换栏输入 /t 就可以,软件会自动在提取完后将/t去除。注意是/,不是\。
上面步骤完成后,点保存规则,关闭规则定义对话框,输入目标地址,发现可以下载了,而且是清晰的大图。
可能对自动命名的图片名称不大满意,我们以网站的图片ID作为文件名:

应用正则,设置文件名

系统选项的文件命名规则,只用filename
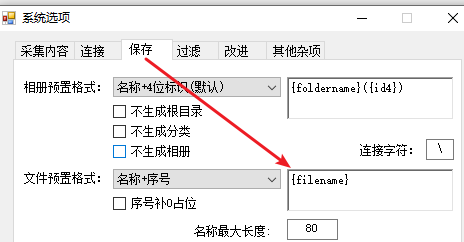

不难发现有个问题,这样只能提取到第一页中的图片,后面翻页部分没有。接下来我们做翻页配置。
2. 5 翻页设置
我们在目标网页中看到,图片列表的下方是有分页信息的,查看网页源代码,通过分析,用 (?<=class="next"><a href=").*?(?=") 可以匹配到下一页的网址。

分页有几种方法,比较简单的可以参考通用网站使用教程中的方法,批量生成网址,然后再继续执行下载。
本文介绍一个更加高级方法,可以适用不同的场景。
在软件中需要做如下操作:
1) 增加变量:next_page
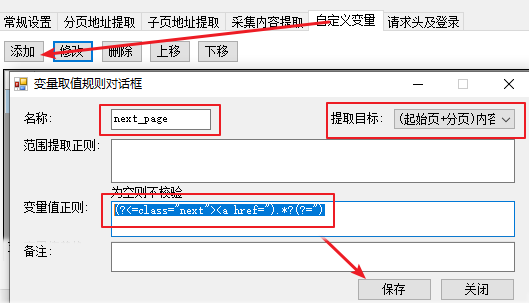
2) 分页地址
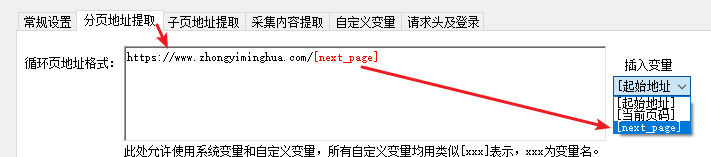
这样就软件就会不断去按下页地址去循环提取,直到提取内容不存在。
再次测试目标地址,400多张就可以下全了!
附常用正则表:
| |
|
| 匹配所有图片 |
((http(s)?://)|\./|\.\./)(\S{1,255})\.(gif|jpg|png|bmp|tiff) |
| |
|
使用啄木鸟下载器的自定义模板配置功能可以扩充支持的网站 - 点此下载最新版软件
